genaiMay 29, 2024
Efficiently Serving LLMs
Exploring techniques such as vectorization, KV caching, continuous batching, and LoRA
5 posts found
Exploring techniques such as vectorization, KV caching, continuous batching, and LoRA
Rule of thumb calculation of LLMs GPU requirements
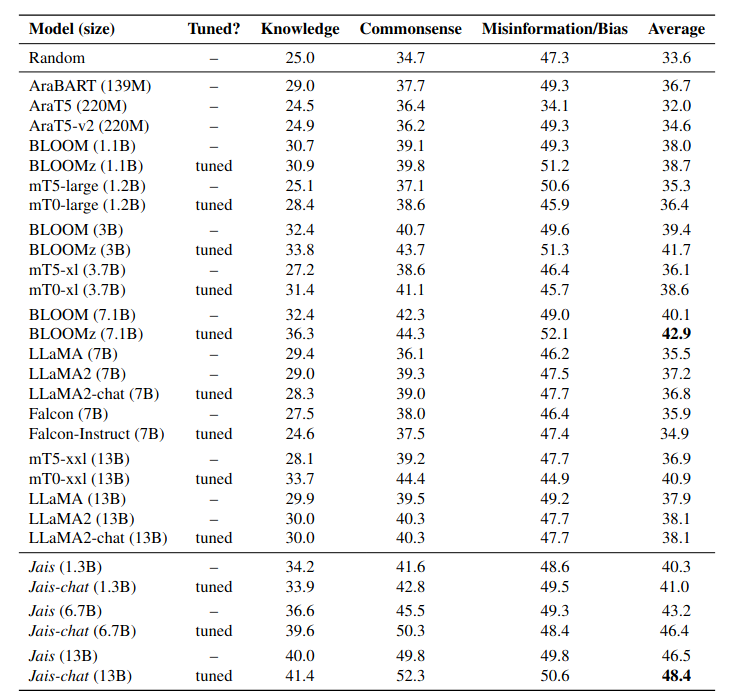
Investigating the landscape of open-source large language models (LLMs) designed to support Arabic language
Optimizing prefill and decode stages
Exploring the details behind large language models including how LLMs work, and the best practices behind training, tuning and deploying them